Tema 1: Conceptos básicos










1.1.1 Introducción al curso
1.1.1.1. Surgimiento
histórico de las bases de datos
Al estudiar el desarrollo
del procesamiento automatizado de datos, en lo que se refiere al aseguramiento
técnico, se habla de diferentes generaciones.
Desde el punto de vista del
aseguramiento matemático y, en particular, del aseguramiento de programas, algunos
autores reconocen tres generaciones:
Solución
de tareas aisladas
Integración
de tareas aisladas en sistemas particulares
Integración de sistemas
particulares en sistemas automatizados de dirección
Este proceso de integración
ocurre paralelamente, aunque no simultáneamente, en dos esferas:
a. Integración de los
programas
Ha estado facilitada por el
uso de lenguajes de programación cada vez más sofisticados y de redactores, que
permiten el acoplamiento de módulos escritos en lenguajes diferentes.
b. Integración de los datos
Se han producido tres
categorías de técnicas para su manipulación:
1. Sistemas orientados a los
dispositivos
Programas y archivos que son
diseñados y empleados de acuerdo con las características físicas de la unidad
central y los periféricos. Cada programa está altamente interconectado con sus
archivos, por lo que la integración de datos de diferentes sistemas es
imposible prácticamente.
2. Sistemas orientados a los
archivos
La lógica de los programas
depende de las técnicas de organización de los archivos (secuencial, directo,
etc.). Cada usuario organiza su archivo de acuerdo con sus necesidades y las
relaciones entre los elementos se establecen a través de los programas de
aplicación.
Esta forma de trabajo
implica redundancia de datos, que trae aparejada mayor gasto de memoria y
complica las operaciones de actualización (modificar un dato donde quiera que
aparezca). Esto aumenta el tiempo de tratamiento y atenta contra la integridad
de la información.
Cuando se habla de integridad, se está
haciendo referencia a que, en todo momento, los datos almacenados estén
correctos en correspondencia con la realidad.
Además, en la vida real, se
establecen relaciones entre los objetos que son muy difíciles de representar u
obtener a partir de sistemas tradicionales de archivos. Por ejemplo, si se
tiene información sobre trabajadores y estudiantes de una facultad, las
aplicaciones requeridas van a definir la manera de organizar y estructurar los
archivos.
Si se desean obtener datos
como promedio de las calificaciones de cada alumno, listado de estudiantes por
grupo, categoría científica y docente de cada profesor, y salario de cada uno,
resulta adecuado establecer dos archivos: uno de profesores y otro de
estudiantes.
¿Qué ocurre si se quieren
establecer vínculos entre los profesores y estudiantes?
Por ejemplo, si se desea
obtener lo siguiente:
Los
estudiantes de un profesor
Los profesores de un
estudiante
De esta manera, se estructuraría
un archivo de profesores y estudiantes que resolvería algunas demandas, pero
sería ineficiente para otras.
Entonces, ¿es posible
representar de manera eficiente, utilizando los medios de cómputo, los casos o
procesos1 de la realidad objetiva, aunque sea, por supuesto, de forma
esquemática, pero en la que se establezcan determinados vínculos entre los
elementos u objetos que forman parte de esos procesos o casos?
Se observa que es posible
hacerlo a través de la utilización de bases de datos (BD) y de los sistemas de
gestión de bases de datos (SGBD) que dirigen su manipulación.
Se tiene, entonces, la
tercera categoría:
3. Sistemas orientados a
base de datos
¿Qué es una base de datos? Aunque
existen distintas formas de definir una base de datos. La siguiente puede
considerarse la más adecuada:
1.1.1.2. Definición
de base de datos
Conjunto de datos
interrelacionados entre sí, almacenados con carácter más o menos permanente en
la computadora. Es decir, puede considerarse una colección de datos variables
en el tiempo.
El software que
permite la utilización y/o la actualización de los datos almacenados en una (o
varias) base(s) de datos por uno o varios usuarios desde diferentes puntos de
vista y a la vez se denomina sistema de gestión de bases de datos (SGBD).
Es importante diferenciar
los términos base de datos y SGBD.
El objetivo fundamental de
un SGBD consiste en suministrar al usuario las herramientas que le permitan
manipular, en términos abstractos, los datos, de tal forma que no le sea
necesario conocer el modo de almacenamiento de los datos en la computadora ni
el método de acceso empleado.
Los programas de aplicación
operan sobre los datos almacenados en la base, utilizando las facilidades que
brindan los SGBD, los que, en la mayoría de los casos, poseen lenguajes
especiales de manipulación de la información que facilitan el trabajo de los
usuarios.
1.1.2. Objetivos de los
Sistema de base de datos
Existen muchas formas de
organizar las bases de datos, pero hay un conjunto de objetivos generales que
deben cumplir todos los SGBD, de modo que faciliten el proceso de diseño de
aplicaciones y que los tratamientos sean más eficientes y rápidos, dando la
mayor flexibilidad posible a los usuarios.
Los objetivos fundamentales
de los SBD son los siguientes:
1.1.2.1. Independencia de
los datos y los programas de aplicación
Se ha observado que, con
archivos tradicionales, la lógica de la aplicación contempla la organización de
los archivos y el método de acceso. Por ejemplo, si por razones de eficiencia
se utiliza un archivo secuencial indexado, el programa de aplicación debe
considerar la existencia de los índices y la secuencia del archivo. Entonces,
es imposible modificar la estructura de almacenamiento o la estrategia de
acceso sin afectar el programa de aplicación (naturalmente, lo que se afecta en
el programa son las partes de éste que tratan los archivos, lo que es ajeno al
problema real que el programa de aplicación necesita resolver). En un SBD,
sería indeseable la existencia de aplicaciones y datos dependientes entre sí,
por dos razones fundamentales:
1. Diferentes aplicaciones
necesitarán diferentes aspectos de los mismos datos (por ejemplo, puede
requerirse la representación decimal o binaria).
2. Se debe modificar la
estructura de almacenamiento o el método de acceso, según los cambios en el
caso o proceso de la realidad sin
necesidad de modificar los
programas de aplicación (también para buscar mayor eficiencia).
La independencia de los
datos se define como la inmunidad de las aplicaciones a los cambios
en la estructura de almacenamiento y en la estrategia de acceso. Todo esto
constituye el objetivo fundamental de los SBD.
1.1.2.2. Minimización de la
redundancia
Se ha comprobado cómo, con
los archivos tradicionales, se produce redundancia de la información. Uno de
los objetivos de los SBD es minimizar la redundancia de los datos. Se dice
disminuirla, no eliminarla, pues, aunque se definen las bases de datos como no
redundantes, en realidad sí existe, pero en un grado no significativo que
servirá para disminuir el tiempo de acceso a los datos o para simplificar el
método de direccionamiento. Lo que se trata de lograr es la eliminación de la
redundancia superflua.
1.1.2.3. Integración y
sincronización de las bases de datos
La integración consiste
en garantizar una respuesta a los requerimientos de diferentes aspectos de los
mismos datos por diferentes usuarios, de forma que, aunque el sistema almacene
la información con cierta estructura y cierto tipo de representación, debe
garantizar entregar al programa de aplicación los datos que solicita y en la
forma en que lo solicita.
Está vinculada a la sincronización,
que consiste en la necesidad de garantizar el acceso múltiple y simultáneo a la
base de datos, de modo que puedan ser compartidos por diferentes usuarios a la
vez. Están relacionadas, ya que lo usual es que diferentes usuarios trabajen
con diferentes enfoques y requieran los mismos datos, pero desde diferentes
puntos de vista.
1.1.2.4 Integridad de los
datos
Consiste en garantizar la no
contradicción entre los datos almacenados, de modo que, en cualquier momento
del tiempo, sean correctos, es decir, que no se detecte inconsistencia entre
los mismos. Está relacionada con la minimización de la redundancia, ya que es
más fácil garantizar la integridad si se elimina ésta.
1.1.2.5. Seguridad y
recuperación
Seguridad (también
llamada protección): garantiza el acceso autorizado a los datos, la forma de
interrumpir cualquier intento de acceso no autorizado, ya sea por error del
usuario o por mala intención.
Recuperación:
permite que el sistema de bases de datos disponga de métodos que garanticen la
restauración de las bases de datos al producirse alguna falla técnica,
interrupción de la energía eléctrica, etc.
1.1.2.6. Facilidad de
manipulación de la información
Los usuarios de una base de
datos pueden acceder a ella con solicitudes para resolver muchos problemas
diferentes. El SBD debe contar con la capacidad de una búsqueda rápida por
diferentes criterios, debe permitir que los usuarios planteen sus demandas de
una forma simple, aislándolo de las complejidades del tratamiento de los
archivos y del direccionamiento de los datos. Los SBD actuales brindan lenguajes
de alto nivel, con diferentes grados de facilidad para el usuario no
programador, que garantizan este objetivo, los llamados sublenguajes de datos.
1.1.2.7. Control
centralizado
Uno de los objetivos más
importantes de los SBD es garantizar el control centralizado de la información.
Permite comprobar, de manera sistemática y única, los datos que se almacenan en
la base de datos, así como el acceso a ella.
Lo anterior implica que debe
existir una persona o un conjunto, que tenga la responsabilidad de los datos
operacionales: el administrador de la base de datos puede considerarse parte
integrante del SBD cuyas funciones se abordarán en la siguiente sesión.
Existen otros objetivos que
deben cumplir los SBD que, en muchos casos, dependen de las condiciones o
requerimientos específicos de utilización del sistema.
1.1.3. REPRESENTACIÓN DE LA
INFORMACIÓN
En el proceso y construcción
de todo sistema informativo automatizado, el diseño de la base de datos ocupa
un lugar importante, a tal punto que ésta puede verse como un proceso
relativamente independiente dentro del diseño del sistema y compuesto por una
serie de etapas. Es por ello que resulta de interés el estudio de los problemas
relacionados con el diseño de las bases de datos y el modelamiento de la
información.
1.1.3.1 Niveles de
abstracción referidos a la información
Cuando se habla de
información, se hace referencia, de forma general, a tres niveles diferentes de
abstracción, tendiéndose a saltar de uno a otro sin establecer una advertencia
previa.
1.1.3.1.1 Nivel del mundo
real
El primero de estos niveles
es el del MUNDO REAL, en el que existen entidades u objetos, que no son más que
elementos que existen y están bien diferenciados entre sí, que poseen
propiedades y entre los cuales se establecen relaciones. Por ejemplo, una silla
es una entidad u objeto, un automóvil, un empleado, un profesor, un estudiante,
que son elementos concretos, también lo son; pero también puede ser no
tangible, como un suceso cualquiera, una cuenta de ahorro o un concepto
abstracto.
Entre las propiedades que
caracterizan a una entidad u objeto destacan el color, el valor monetario, el
nombre, etc.
De las relaciones entre las
entidades u objetos, se abordará más adelante.
La determinación de cierta
entidad u objeto correspondiente a un caso o proceso está muy relacionada con
el nivel de abstracción en el que se esté realizando el análisis. Así, por
ejemplo, si se estudia el comportamiento de un insecto específico en
determinadas condiciones climáticas, las propiedades y relaciones que interesan
son de un cierto tipo; sin embargo, si se estuviera realizando un estudio sobre
las diferentes especies de insectos, serían otros los objetos a definir, así
como las propiedades que los caracterizarían y las relaciones que se
establecerían. Si se estuviera analizando todo el reino animal, serían también
otros los objetos a definir, con sus características y propiedades.
1.1.3.1.2 Nivel del dominio
de las ideas
El segundo nivel es el del
DOMINIO DE LAS IDEAS. Es en el que se decide la información que debe existir en
la base de datos sobre un caso o proceso del mundo real, es decir, qué debe
almacenarse. Aquí, es donde realmente se define el contenido informativo que
representará al caso, proceso o ente de la realidad objetiva que se está analizando.
De modo que, en este nivel, se definen qué objetos y propiedades son
representativos. Ya que sobre estos es necesario almacenar información.
En este nivel, se trabaja
con los conceptos más importantes del modelo de datos, que establecen la
relación entre el mundo real y la información almacenada físicamente en la base
de datos:
Campo o atributo.- es
la unidad menor de información sobre un objeto que se almacena en una base de
datos y representa una propiedad de un objeto; por ejemplo, el color.
Sin embargo, hay que
distinguir entre el nombre o tipo del atributo y el valor del
atributo, ya que un nombre de atributo puede tomar diferentes valores sobre
un cierto conjunto que se denomina dominio. A un valor de un atributo
determinado o definido en el dominio dado, en un cierto momento del tiempo, se
le denomina ocurrencia del atributo.
Ejemplo:

Ahora bien, una colección
identificable de campos asociados es un artículo o registro y representa
un objeto con sus propiedades. Una vez más, es imprescindible distinguir entre nombre
o tipo de artículo y ocurrencia de artículo. Una ocurrencia de artículo
o tupla consiste en un grupo de ocurrencias de campos relacionados,
representando una asociación entre ellos. Por ejemplo, tenemos un artículo
correspondiente al objeto profesor, en un caso o proceso de la realidad que
pretenda representar el comportamiento de una facultad. El nombre o tipo de
artículo puede ser PROFESOR, que esté formado por los siguientes tipos de
campos o atributos:
DNI_PROF: número de DNI del
profesor
NOM_PROF: nombre del
profesor
CAT_DOC: categoría docente del
profesor
DPTO: departamento docente
al que pertenece el profesor
Una ocurrencia de este
artículo puede ser:
12801731 Hernández, Juan PA
Computación.
Un archivo o archivos pueden
ser definidos como un conjunto de ocurrencias de un mismo tipo de artículo.
En la práctica, llama la
atención las colecciones o conjuntos de objetos similares. Además, es necesario
almacenar la información de las mismas propiedades para cada uno de ellos; por
ejemplo, el conjunto de profesores de la facultad.
Entonces, una base de
datos contendrá muchas ocurrencias de cada uno de los tipos de artículos,
lo que implica que la base de datos, por supuesto, también contendrá muchas
ocurrencias de los distintos tipos de atributos.
Uno de los momentos
cruciales en el diseño de un caso de la realidad objetiva que se concreta en
una base de datos es, precisamente, la selección de los conjuntos de objetos y
sus propiedades.
Además, existe otro concepto
muy importante en este nivel que es el concepto de llave o clave.
Se denomina a este último como un atributo o conjunto de de atributos de un
artículo que define que cada ocurrencia de artículo de la base de datos sea
única. En principio, cada artículo tiene una llave, ya que se tiene como
hipótesis que cada elemento u ocurrencia del artículo es diferente de las
demás. Por ejemplo, el DNI del trabajador puede constituir la llave del
artículo trabajador.
1.1.3.1.3 Nivel de los datos
El tercer nivel corresponde
a los datos propiamente dichos, los cuales son representados mediante cadenas
de caracteres o de bits.
En este nivel es necesario tener en
cuenta la diferencia entre tipo de dato y valor del dato. El tipo de dato
corresponde a un atributo o tipo de atributo, que está asociado a un tipo de
artículo correspondiente, mientras que, el valor corresponde a una ocurrencia
del atributo. Sin embargo, una colección de bits o caracteres que representa un
único valor de datos y que puede existir independientemente de cualquier
información que se almacena adquiere significado sólo cuando se le asocia a un
tipo de atributo. Se puede, por ejemplo, almacenar permanentemente los valores
ROJO, AZUL, VERDE, etc.y asociarlos en un momento determinado a un tipo de
atributo a través de los valores que toma, representando una ocurrencia en una
tupla.
1.1.3.2 Relaciones de
correspondencia
Es importante notar que, en
general, habrá asociaciones o relaciones enlazando las entidades básicas.
Estos enlaces se pueden
establecer entre diferentes objetos o tipos de artículos o entre un mismo tipo
de artículo. Por ejemplo, se puede tener una relación entre dos tipos de
objetos: SUMINISTRADOR y PRODUCTO, de modo que un suministrador puede
suministrar muchos productos y que un producto puede ser suministrado por
muchos suministradores y se conoce, además, la CANTIDAD de cada producto que
suministra un suministrador dado. Otro ejemplo pudiera ser con el artículo
PERSONA, sobre el que se pudiera representar la relación "SER MADRE
DE", que no es más que una relación que se establece entre elementos de un
mismo tipo de artículo.
Es necesario profundizar
acerca de los diferentes tipos de relaciones que pueden ocurrir en la práctica
y establecer la correspondencia que existe entre los datos. Esta relación puede
ser simple o compleja.
Por relación simple se entiende
una correspondencia biunívoca (de uno a uno) entre las ocurrencias de los
objetos, o sea, de los artículos. Si, por ejemplo, los objetos o entidades son
Documento_Identidad y Persona, la correspondencia entre ellos es simple: a cada
persona le corresponde un documento de identidad y viceversa.

Si las entidades son Profesor y
Carrera, la relación es más complicada, porque en cada carrera docente trabajan
varios profesores. La terminología usual expresa que la correspondencia de
profesor a carrera es simple, ya que cada profesor es miembro de una única
carrera, mientras que la correspondencia de carrera a profesor es compleja,
pues cada carrera tiene, por lo general, muchos profesores.

Hay cuatro tipos de
relaciones posibles entre dos tipos de artículos A y B: La correspondencia de A
a B puede ser simple y la recíproca compleja. La correspondencia de A a B puede
ser compleja y la recíproca simple. Ambas correspondencias pueden ser complejas
o ambas
pueden ser simples.

Un ejemplo donde ambas
correspondencias son complejas, lo es la relación que se establece entre
PROFESOR y ESTUDIANTE por la impartición de clases, ya que un profesor puede
impartir clases a varios estudiantes, pero, a su vez, un estudiante puede
recibir clases de varios profesores:

Las relaciones pueden tener
diferentes características:
Aunque la mayoría de las
relaciones asocian dos tipos de entidades, éste no es siempre el caso. Por
ejemplo, PROFESOR_HORARIO_ESTUDIANTE. Esto podría representar el hecho de que
un profesor imparte clases a una cierta hora a un cierto estudiante. Esto no es
lo mismo que la combinación PROFESOR_HORARIO y HORARIO_ESTUDIANTE, ya que la
información de que "el profesor P5 imparte clases en el horario H1 al
estudiante E4" dice más que la combinación "el profesor P5 imparte
clases en el horario H1" y "el estudiante E4 recibe clases en el
horario H1"
Las relaciones pueden
establecerse entre un mismo tipo de entidad. Por ejemplo, una asociación entre
un profesor y otro puede venir dada por el hecho de que un profesor sea el jefe
de otros profesores. A este tipo de relación frecuentemente se le llama
relación recursiva.
Es importante señalar que
una asociación entre entidades puede ser considerada en sí como una entidad, ya
que una relación es concebida como un objeto bien diferenciado sobre el cual se
desea almacenar información.
Entonces, un modelo de datos
no es más que la representación de un caso de la realidad objetiva a través de
los objetos, sus propiedades y las relaciones que se establecen entre ellos.
1.1.3.3
Ejemplo integrador
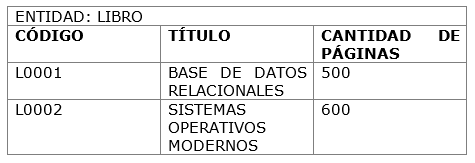
Caso: La
biblioteca
En una
biblioteca, se desea diseñar la base de datos para el control de los préstamos
de libros. De cada libro se conoce el código que lo identifica, su título y la
cantidad de páginas que tiene.
Un libro se
clasifica por una materia y por ésta se clasifican muchos libros. De cada
materia se conoce el código que la identifica y su nombre. Los libros tienen
muchos ejemplares, pero un ejemplar lo es de un solo libro. De cada ejemplar se
sabe su código y su estado de conservación.
Asimismo,
un libro se les puede prestar a muchos usuarios y a un usuario se le puede
prestar muchos ejemplares; del usuario se conoce su DNI, nombre y apellido
paterno, su dirección, y su ocupación
Se
determinan las entidades:
Libro
Materia
Ejemplar
Usuario
Se determinan
los atributos de cada entidad:
Libro =
código que lo identifica, su título y la cantidad de páginas que tiene
Materia =
código que la identifica y nombre
Ejemplar =
código y estado de conservación
Usuario =
DNI, nombre y apellido paterno, dirección y ocupación
Nivel de
datos:
Valores que
tendrá cada atributo de una entidad



Relaciones
de correspondencia









0 comentarios:
Publicar un comentario